システム構築・プログラミングにおいて「疎結合化」は品質向上に欠かせない要素ですが、ワード本来の意味の広さもあり、色々な文脈で語られがです。
様々なWeb文書を見る限り、IT界隈では主として①ソースコードにおける疎結合化と、②システム・アーキテクチャにおける疎結合化に大別できるように感じます。
今回は、この2つの疎結合化の内、特に①(ソースコードに関すること)について、具体例を交えながら個別に内容を考えていきたいと思います。
◇目次
ソースコード論、アーキテクチャ論、2つの「疎結合化」に共通する考え方
アーキテクチャにしても、ソースコードにしても、他の何かと密結合(疎結合の反対語)していると、結合した片方の影響(例えばシステム障害や改修など)が結合相手にも波及してしまい、不効率です。
何か一部の変更をするにしても影響範囲の把握や他部署への確認作業、調整が膨大となり、スピード感をもった改修作業はおぼつかなくなってしまいます。
そこで、一定の括りでコンポーネント化して依存度を落とすことでコストダウンを図り、ビジネスの変化にクイックに対応したり開発組織の効率化を企図するのが中核の考え方と言えます。
ソースコードにおける疎結合化
ソースコードにおける疎結合化は、主に以下のようにソースコードを記述することを指します。
- 個別に実行(テスト)が可能であること。
- 各コンポーネントが特定フレームワークのクラスオブジェクトに依存していないこと(プリミティブ型でのデータ受け渡しや、依存性注入(関連記事)を行う等)。
- レイヤ間(例えばMVCパターンにおけるM-V-C間やアプリケーション層・インフラ(データベース他)層など)の依存関係を簡潔にする。特に相互依存関係などは極力避ける。
- 変数やプロパティなどを複数の関数やクラスで共有しないこと。(関数レベルで疎結合化を行う場合)
尚、近しい概念に関心の分離/Separation Of Concerns(関連記事)や高凝縮度、単一責務原則というワードがありますが、疎結合化とは本質的には別概念と考えてよいかと思っています。
関心の分離ができているコードでも疎結合化の観点では不十分、あるいはその逆のコードも存在し得るということです。
なぜソースコード同士を疎結合にする必要があるのか?→変更容易性を確保し、ソースコードの転用を容易化→ビジネスに勝てるソフトウェアであり続ける
ソフトウェアの使途が完成後に微調整されることや、あるいはコアドメインにとって重要なファクタ・不要な機能が完成後に見つかることが非常に多い、という事実はソフトウェアエンジニアリングの世界に広く知られた経験則です。
有名なエヴァンス氏の翻訳本でも次のような一説があります。
引用:エリック・エヴァンスのドメイン駆動設計 第3章
また、多くのソフトウェアの目的はビジネス効率化であったりマネタイズであったりします。ビジネスや技術環境は常に変化しており、それに伴いソフトウェア自身もニーズや技術の変化に伴い変化していくことが必要です。時にはプラットフォームごと乗り換え(近年の例でいえば、オンプレからクラウドへの移行など)を求められることもあうでしょう。
そういった場合において現在使用しているインフラや古いフレームワークに縛られて転用不可能なソースコードだったり、一部を変更すると影響がシステム全体に波及するような状態では、ビジネスの潮流についていくことはできません。
DDDの話題に限らず、このようなソフトウェアの目的達成のためにも、各モジュールは責務ごとに疎結合≒個別に実行(テスト)が可能であり変更が容易であり、プラットフォームやフレームワークに縛られず転用可能である必要があると言えます。

ソースコード疎結合化の実践
では実際どのようにすればよいのか?実装の場面を再現しながら、簡易的なソースコードや架空のフレームワークなどとともに考えていきます。
他のレイヤ、例えばアプリケーションからインフラ層などを呼び出さない
例えば計算処理の実行中にデータベースから値を取得したり、逆に値を書き込んだりしない努力をすることは重要です。
要は、計算は計算、DB更新はDB更新といった具合に実行箇所をきちんと分け、特に計算処理(ビジネスロジックの処理)は極力メモリリソースで完結することが望ましいと言えます。(当然ながら、リソース上限の問題がある場合はこの限りではありません。)
具体的にコードで見てみましょう。まずはダメコードです。計算処理を行っているはずが、途中でデータベースを呼び出しているため、この計算処理関数はデータベースがある環境でないと実行不能である点が問題と言えます。
ダメコードのイメージ
int Calculation() {
//DBからデータを取得
int baseValue = GetValueFromDatabase();
//何らかの計算
//DBに中間結果をINSERT
RunInsertToDatabase(interimResult);
//何らかの計算
//結果を返却
return result;
}
「こんなコード、普通書かないでしょ。笑」などと思うでしょうか?後述する通り、筆者は昔、実際にこういったダメコードを実装してしまい苦心した記憶があります。感触としては実に初心者プログラマーあるあるな事例のように感じます。
ではどうするべきでしょう?ここはやはり上述した通り、計算は計算として分離し、インフラ(DB等)アクセスは別途行う形式としましょう。
コード修正案
//計算ロジックは、ほかの箇所でDBからとってきた値を引数として受け取る
int Calculation(int baseValue) {
//何らかの計算(DBにはさわらない)
//結果を返却
return result;
}
//実行関数でDB呼び出し、計算、結果をDBに反映、という流れで呼び出す
//(依存性注入による更なる疎結合化の余地あり。後述。)
void Run() {
//DBからデータ取得
int baseValue = GetValueFromDatabase();
//計算を実行
int calculationResult = Calculation(baseValue)
//DBに結果をINSERT
RunInsertToDatabase(calculationResult);
}
この修正によりどういった恩恵があるでしょうか?
最も大きいのは、計算処理とDBアクセス処理が疎結合化されたこと、すなわち計算(ビジネスロジック)とDBアクセスが個別に実行可能となったことが挙げられます。
計算処理(上記例ではCalculation関数)に着目すると、計算処理中にDBにアクセスせず、引数や戻り値も言語仕様の型であるint型となっています。そのためこの関数はこのプロジェクトから引き離しても実行可能であり、データベースなどがない環境でもテストすることができる訳です。
各コンポーネントが特定FWのクラスオブジェクトに依存しない(プリミティブ型の使用、依存性注入)
個別実行可能性の確保において、各コンポーネント(ビジネスロジック)が特定フレームワークのクラスに依存しないことは重要です。
例を考えます。データベースアクセスを提供する架空のフレームワーク(ここでは「DbAccessor」フレームワークとします)があったとして、そのFW内のクラス(ここではDbAccessorResultクラスとします)で結果セットが提供されているとしましょう。
このクラスをビジネスロジック関数に与えてしまうとDbAccessorクラスに依存し個別実行性を損なう(DbAccessorを利用している環境でないと実行できない)ため、関数の外でプリミティブ型(int型など)に変換することを検討します。
ダメコード
int Calculation(DbAccessorResult dbAccessorResult) {
//DbAccessorフレームワークのオブジェクトからDBアクセスの結果を取得
int baseValue = dbAccessorResult.GetDataSet();
//計算処理
return result;
}
このようなコードを書く心理として、「事前変換が面倒だからそのまま計算に流してしまおう」「DbAccessorResultのインスタンスがあれば実行中にDBアクセスができて便利」という声が見て取れます。
しかし上述の通り、これではCalculation関数がDbAccessorフレームワークがない環境では実行不能であり、個別実行可能性を損なう(個別テストや移植ができない)という問題が生じます。
このコードを修正していきましょう。具体的には、Calculation関数とDbAccessorフレームワークを分離するとともに、依存性注入(関連記事)を行います。
コード修正案
//DbAccessorフレームワークのクラスと無関係にする
//(言語仕様型であるint型を使用する)
int Calculation(int baseValue) {
//計算処理
return result;
}
//ビジネスロジックの外側からDbAccessorフレームワークを使用する。
//Run関数自体もDbAccessorフレームワークから自由になるため、
//実態クラスではなくインターフェースで引数を取る。(依存性注入。理由後述。)
void Run(IDbAccessorResult dbAccessorResult) {
//DBアクセス(値をロード)
int baseValue = dbAccessorResult.GetDataSet();
//計算処理(ビジネスロジック)
var resultValue = Calculation(int baseValue);
//DBアクセス(値をINSERT)
dbAccessorResult.RunInsertToDatabase(resultValue);
}
この変更により、Calculation関数はDbAccessorフレームワーク(DbAccessorResultクラス)とは無関係に実行でき、フレームワークが存在しない環境でも実行・テストが出来るようになりました。
(応用編)依存性注入によるRun関数とフレームワークの分離
上記修正案のコードでは依存性注入を行っているという特徴が見られます。具体的には、Run関数の引数に実体クラス(DbAccessorResult)ではなくインターフェース(IDbAccessorResult)を指定している点です。
これは何故でしょうか?それはRun関数自体もDbAccessorフレームワークから自由になるためです。
実態クラスが引数(DbAccessorResult)の場合、Run関数はやはりDbAccessorフレームワークがないと実行できません。他方、フレームワークが提供するインターフェース(IDbAccessorResult)を使用すれば、フレームワークの外でもテストが出来るようになります。
イメージをつかむために、コードで考えてみましょう。
//フレームワークが提供するインターフェース
interface IDbAccessorResult {
int GetDataSet();
RunInsertToDatabase(int resultValue);
}
//フレームワークの実装
class DbAccessorResult : IDbAccessorResult {
int GetDataSet() {
//FWの実装処理
}
RunInsertToDatabase(int resultValue) {
//FWの実装処理
}
}
//独立実行・テスト用のクラス
class DbAccessorResultForTest : IDbAccessorResult {
int GetDataSet() {
//テスト用の簡易の実装
return 0;
}
RunInsertToDatabase(int resultValue) {
//テスト用の簡易の実装
return;
}
}
ここで、IDbAccessorResultインターフェースは、フレームワーク本体を使わなくても、他のコードでもコピーして使うことができる点がポイントです。
この一工夫によりフレームワークがない環境でもRun関数が実行可能となり、更にテスト用実体クラスの利用により個別にテストが実行できるという依存性注入のメリットが実現したと言えます。
関数レベルでの疎結合化:変数やプロパティなどを複数の関数やクラスで共有しない
特にオブジェクト指向言語において、クラス内の関数レベルで疎結合化するか否かは状況によります。可能であれば検討するべきでしょう。
クラスにはプロパティやフィールド変数を設置できるのが一般的です。これらを複数の関数から変更・参照すると状態の管理が困難になる、というのがその理由です。
クラスが巨大になるほど、クラス実装を作業する人数が増えるほど、意識する必要がある論点と言えます。逆に、小規模なクラスや単一責務が明確なクラスであればそこまで厳密に実行する必要もないでしょう。
この疎結合化処理は引数の運用が煩雑になるので、状況次第で検討していくべき論点と考えられます。
具体的な例で考える疎結合化(+関心の分離)①
例えば、「データベースから値を取得して演算した後、結果をエクセルに値を記入して保存」という処理を考えましょう。
エクセルファイルに値を記入できるライブラリは世の中にいくつかあります。ライブラリはある日突然ライセンスが有料化されるかもしれないし、あるいは脆弱性の発見等により別のライブラリに乗り換える必要が生じるかもしれません。こういった時に、処理とライブラリのAPIが密結合していると、ライブラリ載せ替え作業のためにソースコード全体を解体・再構築する必要が出てしまいます。
このような事態に備えてどのようなコードを構築するべきでしょうか?具体的に見ていきます。
//①ライブラリと密結合しているコードの例
//エクセルに値を書き込んで出力するメソッド
void SetValueAndOutputExcelFile() {
//ライブラリAPIオブジェクトを生成
var library = ExcelIOLibrary();
library.FileCreate();
//エクセル書き込む対象となる配列データを
//データベースの2つのテーブルから取得
int[] tableAValues = GetFromDatabase("TabelA");
int[] tableBValues = GetFromDatabase("TabelA");
//2つのテーブルの値を掛け算してエクセルに書き込み処理
//エクセル書き込みはライブラリAPIを呼んで行う。
for (int i = 0; i < tableAValues.Length; i++) {
var value = tableAValues[i] * tableBValues[i];
library.WriteValue(value);
}
//ファイルを保存
library.SaveFile();
}
上記コードでも一応目的は達せられますが、例えばライブラリを変更したいと思ったり、はたまたエクセルファイルではなくCSVファイルに出力したいといった仕様変更があった時にどうなるでしょうか?
データ呼び出しや書き込みといった処理が一連の流れで密結合的に実装されているので、コード全体の修理が必要となってしまいます。
ではどうすればよいのでしょうか?このコードには、①データベースからのデータ取得、②データの加工(演算)、③ライブラリAPIを使ったエクセルへの書き込みと3つのタスクが詰め込まれています。この処理を一つ一つ分解してみましょう。
//②上記①のコードを疎結合化(関心別分離)した例
//データベースから目的の値を取得する処理
Tuple<int[], int[]> GetTableABFromDatabase() {
int[] tableAValues = GetFromDatabase("TabelA");
int[] tableBValues = GetFromDatabase("TabelA");
return new Tuple<int[], int[]>(tableAValues, tableBValues);
}
//エクセルに入力するための値を生成する処理
int[] CaluclationToExcelValues(int[] tableAValues, int[] tableBValues) {
var result = new List<int>();
for (int i = 0; i < tableAValues.Length; i++) {
result.Add(tableAValues[i] * tableBValues[i]);
}
return result.ToArray();
}
//値をエクセルに書き込む処理
//※ライブラリAPIを呼んでいるのはこのメソッドだけなのがポイント
void WriteToExcel(int[] values) {
//ライブラリAPIオブジェクトを生成
var library = ExcelIOLibrary();
library.FileCreate();
foreach (var value in values) {
//エクセル書き込みはライブラリAPIを呼んで行う。
library.WriteValue(value);
}
//ファイルを保存
library.SaveFile();
}
以上のように分解すると、ライブラリ乗り換え等の要請に対して変更が必要なのはWriteToExcelメソッドだけとなり、改修の手間が大幅に省けることになります。より具体的に言うと、前処理で生成されている値などを一切気にすることなく、メソッドが受け取った値を出力する処理だけに集中して作業を行うことができるのです。
このように、「値をDBからとってファイルに書き込む」といった単純な処理でさえ、疎結合化や関心の分離を意識するか否かで変更容易性が変わってくるということが言えます。コーディングの日常で常に意識するべきである、ということです。
具体的な例で考える疎結合化(+関心の分離)② 筆者の失敗談:MVCパターン開発の誤解と反省
MVC(モデル・ビュー・コントローラー)パターンでは、Ruby on Rails等の有名フレームワークにおいてM(モデル層)はニアリイコールでデータベーススキーマ=ORマッパの受け皿という紹介をされます。
そのため「モデル層はDBと密結合してよい」という誤解を生みがちですが、今回の事例を踏まえると完全なる誤解であり後々の問題の火種となります。
ここでは、筆者が過去その誤解のもとダメコードを生産してしまった失敗経験と、そこから学ぶプラクティス、疎結合化の実践を考えたいと思います。
(前提)モデル層には、ORマッパの受け皿の他に「独自の計算」の役割がある
Ruby on Rails等のFWではモデル層はDBのカラムと一致したプロパティを持たせ、RDBの各行をインスタンス化する役割を担います。
他方、MVCアーキテクチャにおいてそのアプリが専門とする計算(コアドメイン)を担うのもモデル層です。
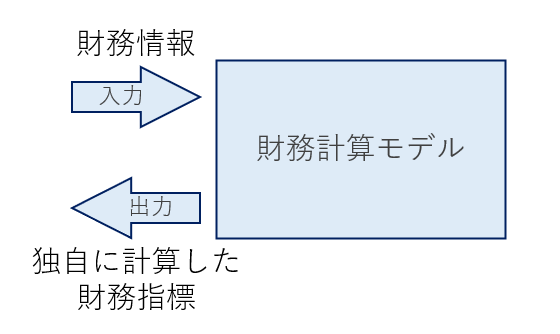
例えばこれから事例とする財務計算システムでは、入力となる財務情報をつかって独自の計算を行い財務指標を出力するといった役割をいいます。こういったものは、通常はモデル層に収めるべし、というのがMVCの基本的考え方です。
財務計算システムの開発で、計算ロジックとDBを密結合させて大失敗
上述の通り、事例として私が過去に作った、財務データを元に一定のロジックで計算して結果を表示・DB格納するシステムを取り上げます。(今後公表予定のプロダクトなので詳細はその時まで伏せますが、今回の議論には支障ありません。)
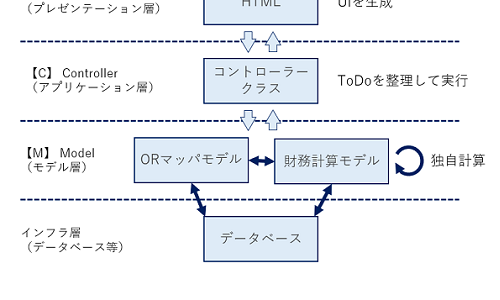
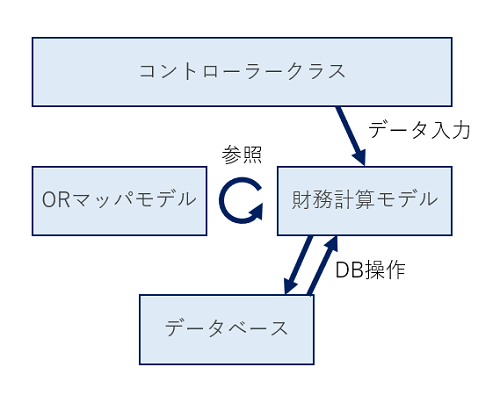
次の図が、私が当初組んだ構成図です。尚、このシステムは、ASP.NET Coreを使用したMVCアーキテクチャで組まれたWebアプリケーションです。
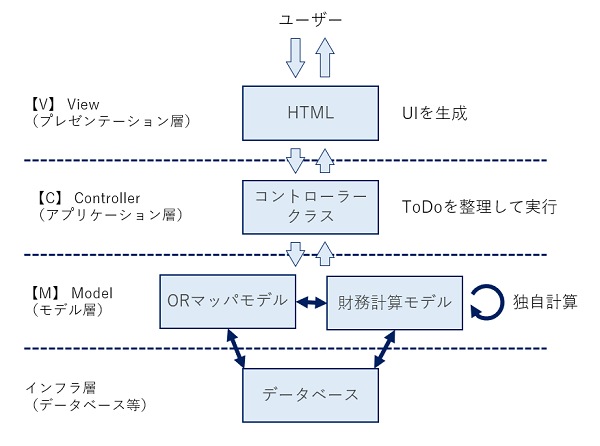
MVC初心者がやりがちな「ファット・コントローラー」(全ロジックをコントローラーに詰め込むアンチパターン)にはなっていない分まだマシです。
しかしながら、財務計算モデルはDBと結合し、計算過程でDBからロードしたり、逆に一部の成果物を計算途中でDBに登録し別の箇所で再度ロードするといった動きをしています。この構成が、後々実際に面倒な問題を引き起こしました。
この財務計算ロジック、他の環境でも役立ちそうなのにDBから引き剥がせない
このシステムが完成してから数年後、中核となっている財務計算モデルを他の箇所でも使用したいという要望がありました。新たな利用環境は、Webアプリではなくデスクトップ上でスタンドアロンで起動するアプリケーションです。
そこで改めてコードを見てみたところ、私はまずい問題に気付きます。コアである財務計算の最中にDBにアクセスする前提のコードが混ざっているため、DBと計算ロジックを引き剥がせないのです。
こうなると、DBがない環境に持ち出すためには、そのロジック自体にも影響が出る可能性もある大手術が必要になってしまいます。このケースでも、かなり処理の流れを変えつつ取り出すことにしたので、相応の工数を必要としました。
本来関係ない「計算ロジック」と「DB」をコード上で結合させたのが最大のミス
財務計算モデルは現実における課題解決を目指したソリューションであり、本来はDBもブラウザーもない世界に存在するモデルであるはずです。
しかしながら、今回の事例では全く関係ない計算ロジックとDBを密結合させて実装した点が失敗でした。
ソフトウェアの構成は、コアドメインとなる中核の計算ロジックを動かすために、コアに関係ない多量のコード、インフラ、UIを必要とするのが通常です。
そういった区分(コアか否か)を明確に行った上、コアとその他の部分が疎結合となるように慎重に分離しておかなければ、何かを変更するたびに大工事が必要となってしまうのです。
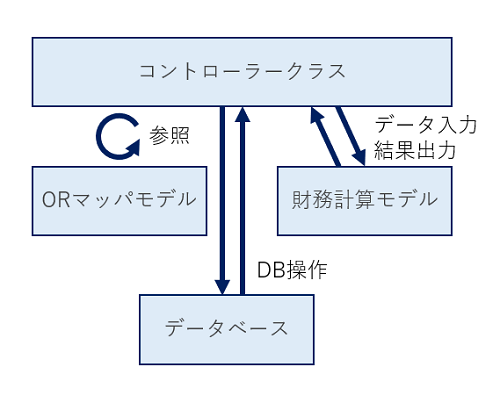
失敗を踏まえ構成を再検討。DBとの結合箇所を再構成する。
冒頭でも書いた通り、モデル層の役割はORマッパとコア計算ロジックの二つです。
この内の計算ロジックに関してはDB(インフラ)ともビューとも分離されている必要とがあります。よって計算ロジック内でDBにアクセスする箇所は全て削除し、コントローラーから処理のためのデータを受け取り、コントローラーに値を返すだけのシンプルなクラスに再構築します。
疎結合化に関する関連記事
本記事でも触れたMVCパターンにおいて、Controllerは疎結合化のための重要責務を負っています。
しかし、こういった重要性はあまり正確に理解されず、しばしば「ファットコントローラー」や「痩せすぎコントローラー」が生産されてしまいます。このような背景も踏まえ、下記参考記事では疎結合化においてControllerが行うべき役割について論じています。併せてご参考ください。
記事筆者へのお問い合わせ、仕事のご依頼
当社では、IT活用をはじめ、業務効率化やM&A、管理会計など幅広い分野でコンサルティング事業・IT開発事業を行っております。
この記事をご覧になり、もし相談してみたい点などがあれば、ぜひ問い合わせフォームまでご連絡ください。
皆様のご投稿をお待ちしております。