お疲れ様です。堺です。
情報活用基盤が活性化しデータ収集の自動化の余地が増える一方、SNSなど眺めていると安易なスクレイピングに取り組んでいる人もいて、法務面とか危なっかしいな・・・という思いもあります。
そこで今回は、スクレイピングとは?実装方法は?実行するにあたっての注意点は?という点について横断的に整理してみたいと思います。
本記事の目的:スクレイピングの機能と実装方法、実務上の注意点の理解
◇目次
スクレイピングの解説
スクレイピング技術は、Webページに自動でアクセスして情報を取ってくる技術であり、API活用と並ぶデータ自動化技術です。(APIについては下の関連記事をご参照ください。)
今回は、スクレイピング用途で代表的なモジュールであり、私自身も使いやすいと感じるPythonのBeautiful Soup 4を利用して紹介します。
実装1:まずはWebサイトにアクセスしてページ内容を取得してみる
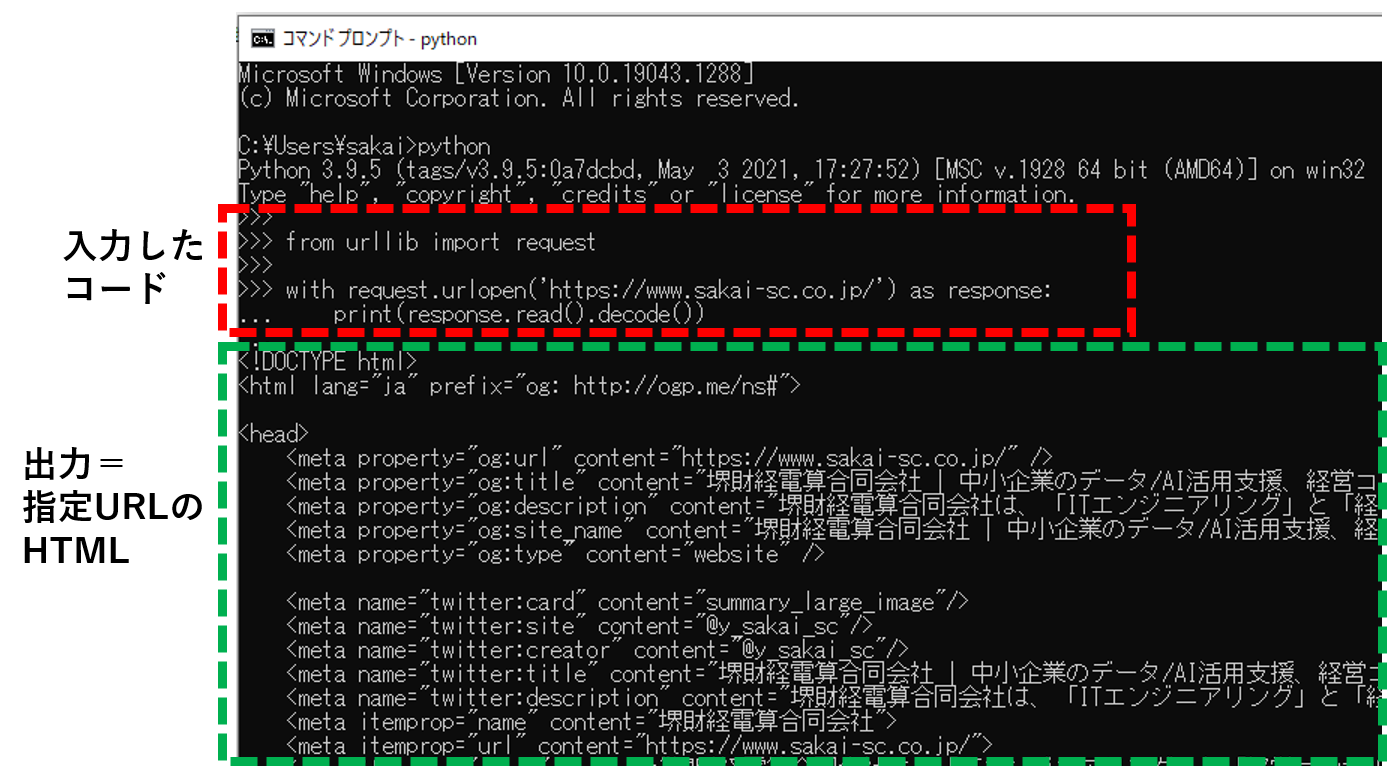
httpリクエストを投げることができるurllibライブラリを使用して、当社コーポレートサイトのHTMLを取得してみます。
Python
from urllib import request
with request.urlopen('https://www.sakai-sc.co.jp/') as response:
print(response.read().decode())

実装2:取得したページ内容をBeautiful Soup 4で解析する
まずはBeautiful Soup 4をPythonにインストールします。
ターミナル
$ pip install bs4
次いで先ほどのPythonコードに解析処理を追加していきます。
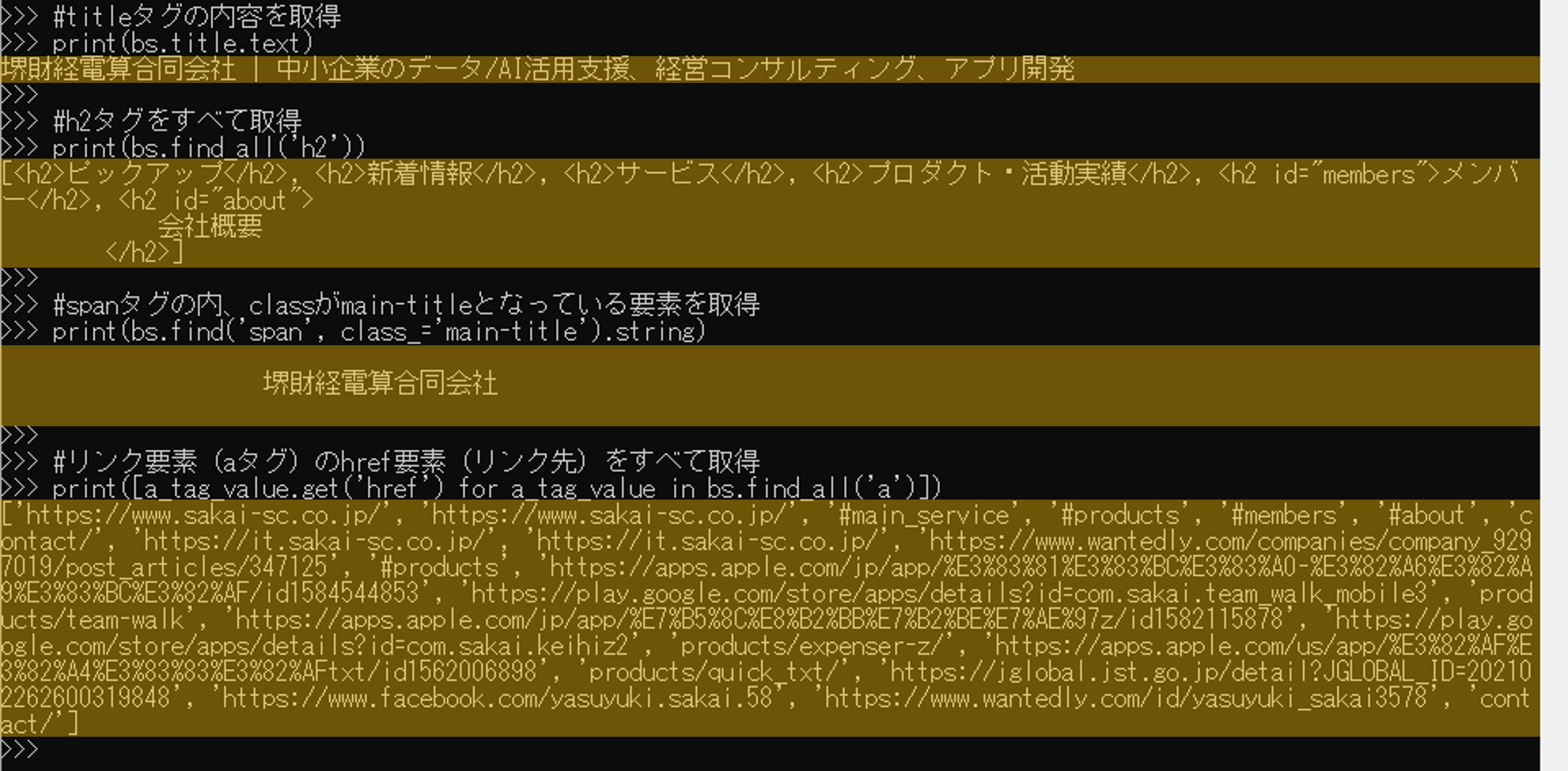
find関数でHTML文書の中の要素を指定して取得できるので、ほしい情報をHTMLソースであらかじめ目星を付けてスクリプトを用意します。find関数は、class指定や属性値などをオプションを指定できるので、かなり細かく値を取得することができます。
また、複数の要素を解析するにはfind_all関数を使用すると便利です。
Python
from urllib import request
from bs4 import BeautifulSoup
import pprint
#ページを読み込んでBeautifulSoupオブジェクトを生成(read関数は内部で呼んでくれるため不要です)
with request.urlopen('https://www.sakai-sc.co.jp/') as response:
bs = BeautifulSoup(response)
#titleタグの内容を取得
print(bs.title.text)
#h2タグのテキストをすべて取得
print(bs.find_all('h2'))
#spanタグの内、classがmain-titleとなっている要素を取得
print(bs.find('span', class_='main-title').string)
#リンク要素(aタグ)のhref要素(リンク先)をすべて取得
print([a_tag_value.get('href') for a_tag_value in bs.find_all('a')])
BeautifulSoupの細かい使い方を知りたい方は、こちら(外部リンク)で日本語ドキュメントを参照できます。
スクレイピングと法令等に関する問題
スクレイピングが他人のWebサイトをターゲットとする以上、著作権の問題や対象サイトへの運営妨害行為にならないか、利用規約などには注意深く気を配る必要があります。
著作権に関しては、「情報解析の目的」であれば利用が許容されますが、その範疇を外れた、例えば自動でコンテンツを収集して自分のサイトに展示するなどの用途はNGである可能性が非常に高いです。(法律に関しては専門家にご相談ください)
また、Webサイトに自動でアクセスするという性質上、過剰なアクセス試行による相手のサーバー運営妨害にならないか、利用規約でスクレイピングを禁じていないかなど、必ず確認するようにしましょう。また必要に応じてサイト運営者の許可を取り付けましょう。
不用意にスクレイピングを仕掛けると、最悪の場合、賠償問題や刑事事件等にも発展する可能性もあることに十分ご注意ください。
この話題ではもはや定番であり、実際に逮捕者が出てしまった(但し後に不起訴)岡崎市立中央図書館事件(外部リンク)についても是非ご参照ください。
実務上の利用難度に対する所感と結び
この様に、技術的には可能ではあっても運用面の難しさでは依然として課題が多いのが現状という認識です。
現代の情報経済の更なる発展のためには、ソフトウェアが情報をより活用できるようにする体制づくり(例えばAPI設置とアクセス量に対する助成金など?)は国を挙げて取り組むべきではないかと、常々感じるところではあります。
今後の言論の進展があることを祈りつつ、自分としても少しずつ発言していくようにしたいと思います。
駄文にお目通しいただきありがとうございました。引き続きよろしくお願い申し上げます。
小規模ITシステムの構築ならお任せください
当社では、主に中堅・中小企業様向けに、「小規模IT構築サービス」を提供しております。
パソコンで動作する計算・ファイル作成ソフトや、オリジナルのスマートフォンアプリとクラウド基盤を組み合わせた業務効率化など、様々な形態の小規模・独自システムを開発します。
構想段階でも結構ですので、ぜひお気軽にお問い合わせください。また、こちらにパンフレットを用意しておりますので、ご参考いただけますと幸いです。