お世話様です。堺です。
私がプロジェクトで機械学習を用いるときは、ブラウザ上で開発できるGoogle Colaboratoryを使って機械学習モデルを生成し、スマートフォンなどに搭載しています。
環境構築をスキップ出来て便利な一方、本格的な開発を始めると、教師データなど大規模データの供給に頭を悩ますことになります。
例えば、
- アップロード時間がかかりすぎる・・・
- タイムアウトしてアップロードできない・・・
- TPUを使うとメモリ不足でクラッシュするんだけど・・・
- え?この従量課金請求は何???
などなど。
この様な過去の私の悩みと失敗も踏まえて、今回は効率よくColabにデータを流し込む方法をまとめてみようと思います。
この記事の目標:Google Driveから、GCPからのファイル供給の必要性理解、実装手順を確認
◇目次
まずは基本、直接アップロード
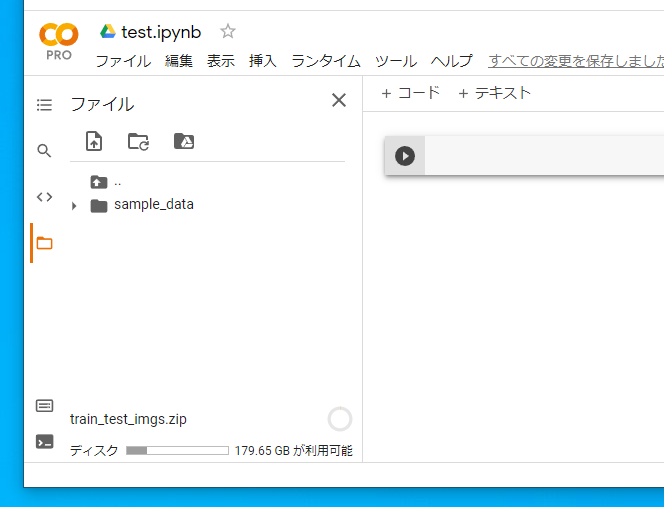
Colabでは、左側のフォルダーアイコンをクリックすれば、そのColabファイル内でアクセス可能なストレージがブラウジングされます。
ここにファイルをドロップダウンすることで、ファイルをアップロードでき、コード内からアクセスできるようになります。
とはいえ、ここのI/O速度はかなり遅く、タイムアウトも起きます。よって、この方法は軽量・少数ファイルに限られます。
Google Driveをマウントしてファイルを供給
大量データ供給のスタンダードはこの方法です。
「マウントする」というのは、ざっくりいうと外付けHDDディスクをマシンに接続するようなイメージで、Google Driveの中のファイルにColabからアクセスできるようになります。
具体的にマウントするには、以下のコードを実行します。
Python
from google.colab import drive
drive.mount('/content/drive')
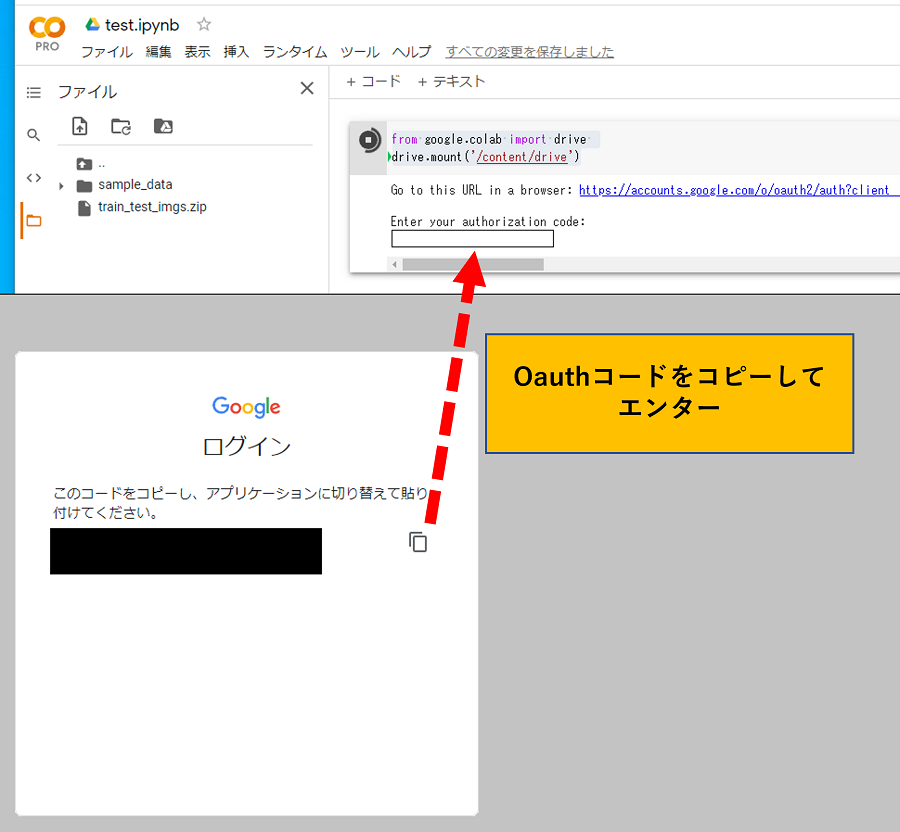
下の画像の様にOAuthが立ち上がるので、Google Driveを接続するアカウントを選択し、コードをコピーして接続完了です。
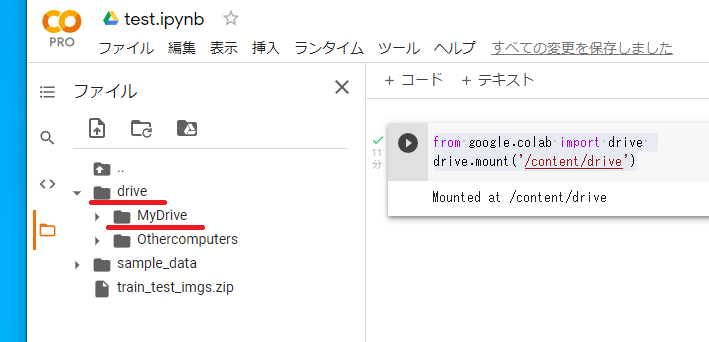
成功すると、ファイル窓にdriveフォルダーが追加されています。
この中のMyDriveフォルダーの中に接続したアカウントのGoogle Driveのマイドライブの内容が格納されています。

Google Driveをマウントしてもやり様によっては時間がかかる
かくしてColabからGoogle Driveにアクセスできるようになったのですが、注意すべきは、driveフォルダーへのI/Oアクセス速度も、直接アップロードよりはマシとはいえ結構遅めという点です。Colab直下よりは明らかに遅いです。
経験的には、大容量ファイル(ZIPなど)は何とかなるものの、個数が多めのファイル群を扱うと、極端に長い時間がかかる場合があります。
対策としては、教師データなど使用できるデータを決めたら、ローカル環境でZIPファイルを作ってDriveにアップロードし、Colabから拾いに行くのが良いかと思います。
私の場合は、Google DriveにZIPファイルを置いて、Pythonのzipfileモジュールで解凍してColab直下に持ってきます。この方法だと高速にデータをロードできます。
Tensorflow × TPUユーザー必携、GCSをColabに連携させる
TPUで大量データを学習させる場合、GPUランタイムに比べて低水準でメモリがいっぱいになります。
そのため、教師データをTFRecordとして一旦書き出して、TPUに供給するという手続きが必要になってきます。
その場合、TPUはTFRecordをファイルからは直接読むことができず、TFRecordをGCS(Google Cloud Strage)に格納してそこからデータを取って来ることが求められます。
(補足:CPU/GPUランタイムであれば、メモリに乗りきらないデータはGeneratorで供給すればいいのですが、TPUの場合は現状これに対応していないようで、GCSからTFRecordファイルを読み込ませる必要が出てきます。)
GCS連携の準備、ファイル操作の実装
まずはGCSにストレージを作っておきます。
Colabからデータを取るときに必要となる情報は、①ストレージ名、②ストレージが属するプロジェクトID、の2つです(下の画像の黒塗り2か所です)。あらかじめ控えておきましょう。
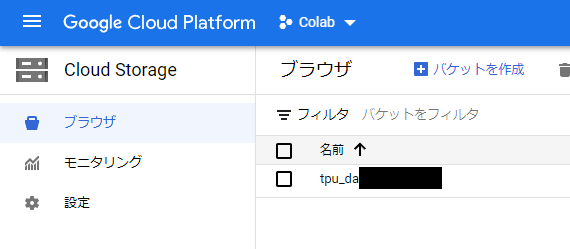
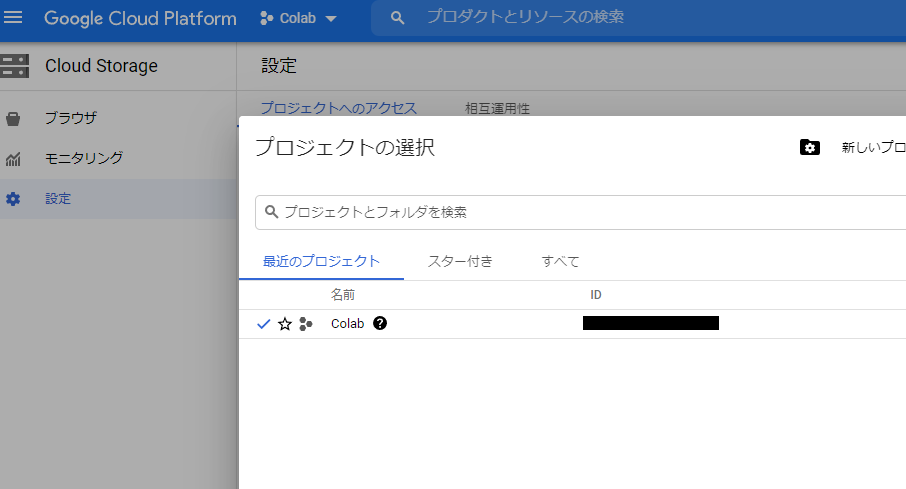
続いて、Colab側から作成したGCSと連携します。
Python
from google.colab import auth
auth.authenticate_user()
要領はGoogle Driveの時と同じです。コードを取得・ペーストして認証します。
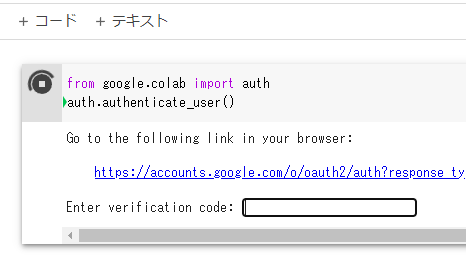
GCSにアクセス出来たら、早速ファイル操作を行います。
プロジェクトIDとストレージ名は、各位上の画像で確認した値を入れ替えてください。
Python
TFRECORD_GCS_DIRPATH = 'gs://ストレージ名/'
#GCPプロジェクトにアクセス ※他の操作を行う前にこれを実行
!gcloud config set project {'プロジェクトID'}
#GCS内のファイル一覧を取得
files = !gsutil ls $TFRECORD_GCS_DIRPATH
#GCSにファイルをコピー
!gsutil cp 'test.jpg' $TFRECORD_GCS_DIRPATH
#GCS内のファイルを削除
file_path = TFRECORD_GCS_DIRPATH + 'test.jpg'
!gsutil rm -f $file_path
この様な形で、GCSのファイルにアクセスできるようになりました。
尚、一応おさらいしておくと、ColabではIPythonがデフォルトで使用でき、行頭に!を付けることでシェルコマンドを実行可能です。
ここでは、GCSアクセス用コマンドとしてgsutilを利用しています。コマンド中では、$マークを付けることでPython側の変数を埋め込みできます。
GCSの中のTFRecordファイルからTensorflowにデータを送る際は、以下のようにパスを指定します。
ポイントは、tf.data.TFRecordDatasetの引数の文字列の指定部分です。
Python
trainset = tf.data.TFRecordDataset(['gs://ストレージ名/test.tfrecord']).map(deserialize_example).shuffle(2048).repeat().batch(batch_size)
model.fit(trainset, epochs=300, steps_per_epoch=train_length/batch_size, verbose=1, batch_size=batch_size)
最後に注意点:GCSは保存容量に応じて従量課金がかかる
標題の通りですね。
GCSに教師データのような大容量データを入れっぱなしにしていると、気づかないうちに結構なコストが発生してしまう場合があります。(というか、一回やらかしました・・・)
TPUの学習速度は快適ですが、くれぐれも後始末を忘れないように注意しましょう。
結び:操作のポイントをおさえて、便利なColabをより活用しましょう!
冒頭にも書きましたが、PythonやGPUの環境構築が必要ないColabは、私のような開発者にはとてもありがたい存在です。
慣れればサクサク使えますし、皆様もぜひこの記事の内容を踏まえて楽しくご活用ください。
お目通しいただきありがとうございました。
記事筆者へのお問い合わせ、仕事のご依頼
当社では、IT活用をはじめ、業務効率化やM&A、管理会計など幅広い分野でコンサルティング事業・IT開発事業を行っております。
この記事をご覧になり、もし相談してみたい点などがあれば、ぜひ問い合わせフォームまでご連絡ください。
皆様のご投稿をお待ちしております。